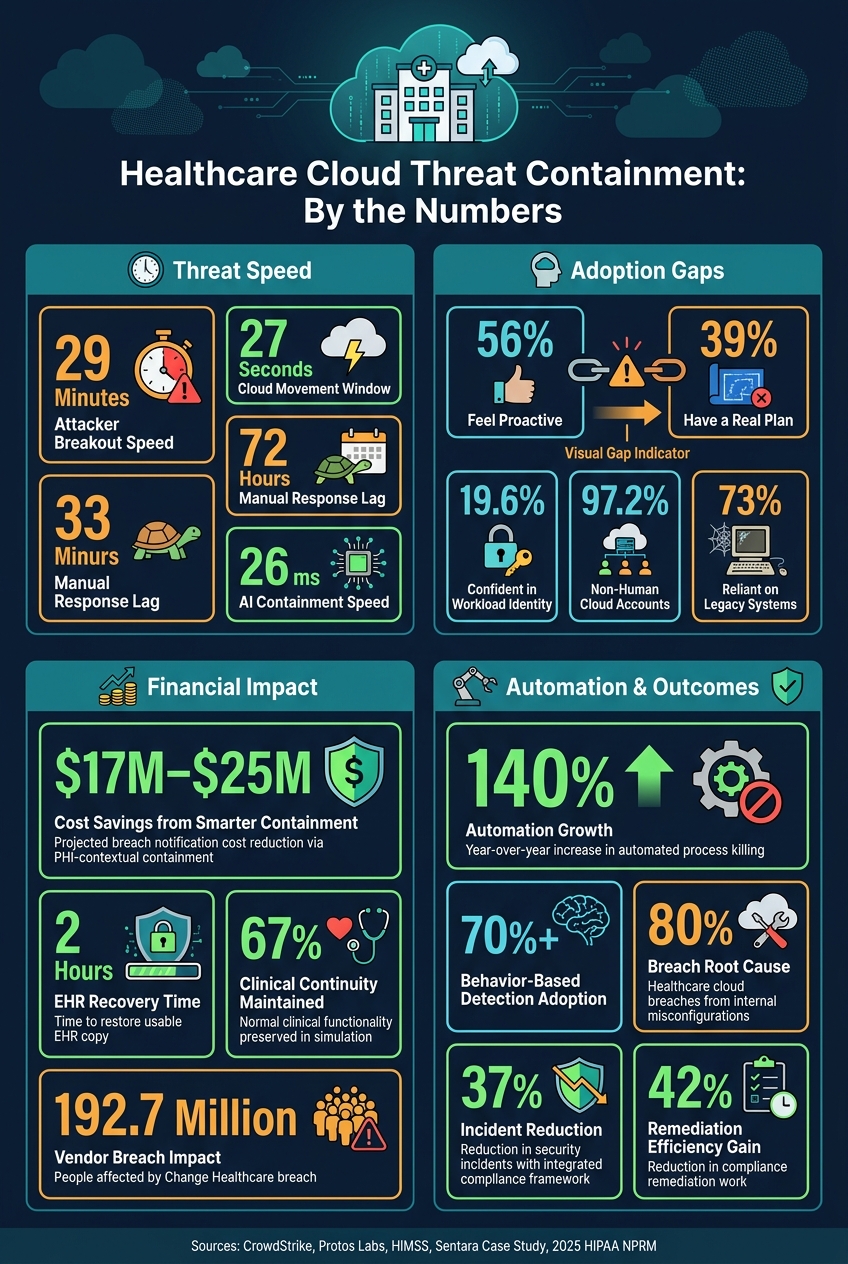
In healthcare, threat containment has to happen in minutes, not hours. I’d sum up the article like this: attackers can move in 29 minutes on average, cloud movement can happen in 27 seconds, and many teams still take far too long to lock down access, isolate workloads, and keep care systems online.
If you want the short answer, here it is:
- Containment is the part between detection and recovery
- It aims to stop spread fast and keep the EHR, pharmacy, and care systems available
- The main control areas are identity, network, runtime, cloud settings, and data
- The methods that stand out most are token/session revocation, microsegmentation, soft workload quarantine, policy checks, and isolated recovery environments
- The biggest weak spots are legacy systems, poor workload identity control, cross-cloud blind spots, and vendor access
I also see a clear pattern in the evidence:
- Manual response can lag far behind attacker movement
- Narrow containment works better than broad shutdowns when care must continue
- An isolated recovery setup can bring back a usable EHR copy in about 2 hours
- Better PHI context can cut projected notification costs by $17 million to $25 million
- Many teams say they are ahead of the problem, but only 39% have a defined cloud-native containment plan
Here’s the bottom line: the article shows that healthcare containment is no longer just “find and fix.” It’s about cutting off bad identities, blocking lateral movement, limiting PHI exposure, and keeping clinical work going at the same time.
| Focus area | What I’d take from the article |
|---|---|
| Speed | Attackers move far faster than human-only response |
| Main goal | Stop spread before core care systems are hit |
| Best-used controls | Identity, segmentation, runtime isolation, data controls |
| Strong use cases | EHR lifeboat environments and PHI-aware containment |
| Main blockers | Old systems, non-human identities, third-party vendor risk management, poor ownership mapping |
If you work in healthcare IT, the message is simple: don’t treat containment as one tool or one step. Treat it as a set of controls that can cut access and isolate risk before downtime turns into a patient care issue.
Healthcare Cloud Threat Containment: Key Stats & Gaps at a Glance
Cloud-native threat containment in healthcare
In healthcare IT, cloud-native threat containment is about cutting off a bad identity or workload before it reaches the EHR or other clinical systems that can't go down.
That line matters a lot in HDO settings. A stolen credential or a cloud setup mistake can open a route from general IT into clinical zones. Containment is there to shut that route fast and limit blast radius. In practice, that means containment isn't one product or one switch you flip. It's a stack of controls working at the same time.
Containment versus detection and recovery
Detection, containment, and recovery answer different questions.
Detection tells you whether you spotted the attack. Recovery tells you how long it took to get back on your feet. But neither one shows how far the attacker got before being stopped, or how many systems stayed untouched.
That's why containment speed and blast-radius reduction need their own metrics. In healthcare, those measures matter a lot because the gap between "caught" and "contained" can be the gap between an IT issue and a clinical disruption.
Recent threat-intelligence data shows attackers can reach critical systems within minutes of initial access.
Core control layers
Cloud-native containment in healthcare works best as a set of layers. Each one blocks a different route an attacker might take through the environment.
| Control Layer | What It Does | Why It Matters in Healthcare |
|---|---|---|
| Identity | Session revocation, JIT access, phishing-resistant MFA | Stops compromised tokens from calling protected APIs [6] |
| Network | Microsegmentation between IT, IoMT, and EHR zones | Limits lateral movement from workstations to clinical systems [3] |
| Runtime | Container image scanning and real-time workload protection | Stops malicious code at runtime [5] |
| Cloud control plane | Automated CSPM with remediation | Closes misconfigurations attackers use to escalate access [1] |
| Data | HSM-backed key management, PHI access monitoring | Flags bulk exports and abnormal API activity [6] |
The research points in the same direction: containment has to cover the full credential and access chain. It's not enough to focus only on ransomware after it starts. You also have to deal with credential-stealing malware and stolen credentials earlier in the attack path.
"Fixing the downstream (ransomware brand) problem without fixing the upstream (access generation) problem is insufficient." - Protos Labs Threat Intelligence [3]
In many cases, identity and session controls are the first place teams can cut off spread after credentials are stolen.
The next question is which of these layers recent studies show actually reduce spread in HDO environments.
sbb-itb-535baee
What recent studies say
With the control layers mapped out, the next step is simple: do they work when things go sideways?
Reported outcomes and recurring patterns
Recent studies point to a big speed gap. eCrime breakout time averages about 29 minutes, while manual containment can take as long as 72 hours [2][3]. That gap matters. If an attacker can move in under half an hour, a slow, manual response can leave teams playing catch-up from the start.
At the same time, automated process killing is moving up fast. Usage has climbed 140% year over year, and more than 70% of organizations now rely on behavior-based detections [7]. That suggests a clear shift: teams are leaning less on static rules alone and more on systems that spot odd behavior as it happens.
Integrated controls also improve visibility. In healthcare tests, AI-driven containment frameworks reached 26 ms detection-and-response latency and an AUC of 0.98 [4]. Put plainly, those systems reacted almost at once and performed at a very high level in separating bad activity from normal behavior.
There’s also a practical upside to tying PHI classification and lineage to access telemetry. Instead of shutting down whole systems, teams can contain only the identities or data tied to the event. In one crisis simulation, that narrower response cut projected breach notification costs by $17 million to $25 million [9]. That’s a huge difference, especially in healthcare, where a broad shutdown can ripple into patient care, billing, and legal follow-up all at once.
The two containment approaches with the strongest HDO-specific evidence are below:
| Containment Approach | Primary Benefit | Healthcare Relevance |
|---|---|---|
| Isolated Recovery Environment (IRE) | Activates a clinical "lifeboat" in about 2 hours [2] | Sustains EHR access when the primary network is down [2] |
| Data-Contextual Containment | Reduces notification costs and legal liability [9] | Isolates only affected PHI segments while maintaining clinical continuity [8][9] |
Sentara deployed an isolated recovery environment in 10 weeks and restored a usable EHR copy in about two hours, preserving 67% of normal clinical functionality in simulation [2]. That kind of result stands out because it moves the conversation beyond theory. Even so, the proof base is still uneven.
Limits and evidence gaps
The gains look promising, but maturity and adoption don’t line up yet. 56% of organizations describe their posture as proactive, but only 39% have a defined cloud-native containment strategy [10]. In other words, many teams feel ahead of the problem, yet far fewer have a clear plan built for the systems they now run.
Identity management is another weak spot. Only 19.6% of security professionals say they feel confident managing workload identities, even though those identities account for 97.2% of cloud accounts [7]. That’s a rough mismatch. If most cloud accounts are non-human, but few teams feel ready to manage them well, containment can break down in places people barely see.
Older platforms add more friction. Legacy systems such as AIX and HP-UX make containment automation harder [2]. And even when scanning improves, human remediation still leaves 5.5% of running workloads exposed [7]. That last piece is worth sitting with: better detection helps, but cleanup still depends on people, handoffs, and time.
Containment methods used in practice
Here’s the practical version of those findings: containment in healthcare usually happens across four layers - identity, network, workload, and data.
Identity and session containment
Start with RBAC and SSO using OIDC/SAML to enforce minimum-necessary access. If a session gets flagged, revoke tokens and trigger an MFA re-check [11]. That gives teams a clean way to cut access without waiting around.
Short-lived credentials help shrink the blast radius, which matters even more when 51% of workload identities are inactive [14]. If an identity isn’t being used, it’s still a risk if it stays alive too long.
Teams also need break-glass overrides for Code Blue events, along with a complete audit trail for HIPAA [13]. In a hospital, speed matters. But so does knowing exactly who accessed what, and when.
Network, workload, and runtime isolation
On the network side, many teams use microsegmentation through Kubernetes Network Policies. A common starting point is default-deny ingress and egress across all namespaces, then adding back only the traffic that PHI-handling services need [11].
That simple shift does a lot of work. If a public-facing API gets hit, those rules can stop it from moving laterally into internal EHR databases or clinical data stores.
Still, network controls alone don’t seal every gap. Runtime and data controls have to cover what’s left.
In clinical settings, teams often rely on soft quarantine because live encounters can’t just stop in the middle. eBPF sensors can cut a pod’s external access while the encounter finishes, which is a practical middle ground. The overhead is low too: 1–2.5% CPU and 1% memory per node [12].
To tighten runtime isolation, use Pod Security Standards to block privileged containers and hostPath mounts. Pair that with Falco to flag unusual execution in real time [5][11].
Data-layer and posture enforcement
At the data layer, the focus is straightforward: protect PHI at rest and in transit, and keep cloud settings from drifting into unsafe territory.
The core controls are encryption through Key Management Systems (KMS) and mutual TLS (mTLS) for service-to-service traffic [11]. Secrets should live in external KMS-connected stores, not inside container images or plain environment variables. Putting secrets there is like leaving a spare key under the doormat. It works until someone looks.
For posture checks, admission controllers verify image signatures before deployment, while policy-as-code keeps scanning configs for risky exposure, such as an open S3 bucket.
The 2025 HIPAA Security Rule NPRM changes the stakes here. It moves both encryption of ePHI at rest and in transit, and MFA, from "Addressable" to "Required" [15]. That means data-layer controls are no longer something teams can treat as optional.
Taken together, these layers shape the containment posture HDOs need to keep clinical systems running during an incident.
| Containment Layer | Primary Mechanism | Speed | Operational Impact | Healthcare Fit |
|---|---|---|---|---|
| Identity | Token revocation, MFA re-challenge | Fast | Moderate (can block users) | Essential for minimum necessary PHI access |
| Network | Microsegmentation, egress blocking | Moderate | Moderate (risk of app breakage) | Critical for isolating PHI databases |
| Workload/Runtime | Soft quarantine via eBPF, Falco | Instant | Low (vs. pod termination) | Strong fit for 24/7 clinical operations |
| Data/Posture | KMS encryption, admission control | Proactive | Low | Required under the 2025 HIPAA NPRM [15] |
The next constraint is operational: HDOs must deploy these controls without disrupting care.
Healthcare adoption constraints and implementation takeaways
Constraints in HDO environments
Those controls only help if hospitals can put them in place without disrupting care.
That’s the hard part in HDO environments. Clinical systems can’t be patched on a normal IT schedule, so containment has to fit around uptime demands and vendor limits. Legacy infrastructure makes this even harder. 73% of healthcare organizations still rely on outdated systems [16]. And while 85% of IT leaders say those systems threaten their organization's future, only 9% have made removal a priority [16]. In plain terms, many containment policies have to work around systems that were never built to support modern security controls.
Visibility is another problem. Many cloud-native tools show telemetry from only one provider, which leaves security teams without the cross-cloud view they need to connect threat findings to the right asset owners or clinical workflows [16]. At the same time, PHI doesn’t stay neatly inside the EHR. It spreads into analytics platforms, logs, SaaS exports, and vendor tools, often with no assigned data owner and no control that can actually be enforced [16].
Third-party access adds one more weak spot. The Change Healthcare breach affected 192.7 million people [16]. That number is hard to ignore. It shows that vendor access paths can carry the same risk as internal ones, and in many cases, they get less review.
Evidence-based priorities for security leaders
That makes ownership mapping the first containment job.
Before enforcing any containment policy, security teams should map every system that creates, receives, maintains, or transmits ePHI and assign each one to a named owner and a clinical service [16]. A simple way to pressure-test that map is to compare the billing inventory, cloud inventory, and CMDB. If those records don’t line up, there’s probably missing ownership.
From there, use a phased zero-trust roadmap:
- Centralize identity and MFA first
- Microsegment workloads next
- Automate compliance monitoring after that [17]
This order matters. 80% of healthcare cloud breaches come from internal misconfigurations [18]. So a big share of the risk comes from governance and process gaps, not just missing tools.
Compliance evidence should also be generated automatically through policy-as-code and drift detection. An integrated compliance and security framework can reduce security incidents by 37% and cut compliance remediation work by 42% [18].
Containment decisions also need to connect to enterprise and third-party risk workflows. Vendor accounts should have time-bound access, recorded sessions, and scoped roles [17]. Exceptions should come with expiration dates and clear owners [16]. Platforms like Censinet RiskOps™ can support this governance layer by helping HDOs manage third-party and enterprise risk assessments, track PHI-related vendor exposure, and keep visibility across clinical applications and supply chains.
FAQs
How fast should containment happen in healthcare?
In healthcare IT, containment needs to happen fast. The longer a threat stays active, the more likely it is to disrupt patient care, extend downtime, and spread across systems.
The numbers make that pretty clear. Keeping Mean Time to Contain (MTTC) below 4 hours cuts care disruptions by 58%. Even so, the industry average sits at 7 hours, while top-performing organizations bring threats under control in 4.2 hours. And with automation, that window can shrink from hours to minutes.
Which control layer should we implement first?
Start with governance and asset tiers, with Tier 0 and Tier 1 systems at the top of the list. That includes identity management, EHR, and medication platforms.
It also makes sense to begin with the Essential goals in the HPH CPGs. These first steps help close common gaps, like weak passwords, phishing, and unverified vendors, before you move to stronger controls such as network segmentation or behavior-based analytics.
Censinet RiskOps™ can help identify these priorities through automated assessments and benchmarking.
How can hospitals contain threats without disrupting care?
Hospitals can limit threats without disrupting care by focusing on early detection and automated, coordinated response. Real-time monitoring and behavioral analytics help teams spot unusual data access or unauthorized device activity before an incident grows.
When a threat appears, automated systems can isolate affected segments to cut the impact while unaffected clinical operations keep running. Censinet RiskOps™ helps by streamlining risk assessments and managing third-party vulnerabilities.
